Are Sleep Trackers Effective?
Statistical learning techniques are used to determine if it is possible to effectively predict time asleep from data that would be available without the aid of a sleep tracker.
 Image credit: Lukas Blazek
Image credit: Lukas Blazek
1 Abstract
Personal sleep tracking devices are becoming more and more popular. Statistical learning techniques are used to determine if it is possible to effectively predict time asleep from data that would be available without the aid of a sleep tracker.
2 Introduction
It is without question that sleep is a very important process for both learning and memory. 1 For optimal learning, sleep, both in quality and quantity, is required before and after learning. Depending on certain demographic factors, there are different sleep prescriptions, but for adults, a minimum of seven hours is needed to avoid impairment. 2 Recently, the link between shift work and cancer has been well established. While more study is needed, there seems to be growing evidence that lack of sleep may play a strong causal role in many cancers. 3 As the public has become more aware of the importance of sleep, the use of “smart” devices to track sleep has risen. Many sleep trackers provide a wealth of information including not only time asleep, but also details such as time spent in the various stages of sleep. (Light, deep, REM.)
The effectiveness of these sleep devices is still in question. 4 While the breadth of data that they make available is interesting, the most important by far is the total time asleep. (Asleep being defined clinically, not by simply being in bed.) The additional data, such as time in REM sleep, is interesting, however it is unclear what the target values should be, and more importantly, how we could affect change in these numbers. In contrast, there is a wealth of advice on how to increase quality and time spent asleep. 5 If total time asleep is the only data worth tracking, is a smart device actually necessary? Is it possible to estimate time asleep based on simple metrics such as time spent in bed?
Statistical learning techniques were applied to a four month sample of data from a Fitbit 6 user. Time spent in bed was used to predict total time asleep. The results indicate that this prediction can be made with a reasonably small amount of error. However, practical and statistical limitations suggest the need for further investigation.
3 Methods
3.1 Data
The data was accessed via the data export tool provided by Fitbit. 7 It was collected using a Fitbit Versa 2 by a single subject, a 32 year old adult male living in Ohio and working as a professor. The Fitbit Versa 2 uses both motion and heart rate variability 8 to predict when the user is sleeping. The collection dates were a series of consecutive days in autumn of 2018. The two quantities of interest in the data are the time spent asleep and the time spent in bed each time the user sleeps. (A user could sleep more than once a day. For example, a two hour nap in the afternoon.) If the former can be predicted from the latter, the device seems unnecessary. (Time spent in bed could simply be tracked manually by a user. Although, it should be noted that one of the benefits of the devices is the automatic tracking of this quantity, which is probably more accurate than manual human tracking.)
3.2 Modeling
In order to predict time asleep given time in bed, three modeling techniques were considered: linear models, k-nearest neighbors models, and tree models. No transformations were considered with the linear model. Default tuning parameters were used to train the two non-parametric models. Only time in bed was used as a predictor variable.
3.3 Evaluation
To evaluate the ability to predict time asleep with these models, the data was split into estimation, validation, and testing sets. Because of the dependence structure of the data, that is the consecutive nature of the days, the data was split chronologically. That is, the test set is the last 20% of the data chronologically. (And similarly for the validation data.) This is done to evaluate the ability to predict future nights of sleep from past data. Error metrics and graphics are reported using the validation data in the Results section.
4 Results
| model | rmse |
|---|---|
| Linear | 8.444805 |
| K-Nearest Neighbors | 11.692058 |
| Tree | 15.112509 |
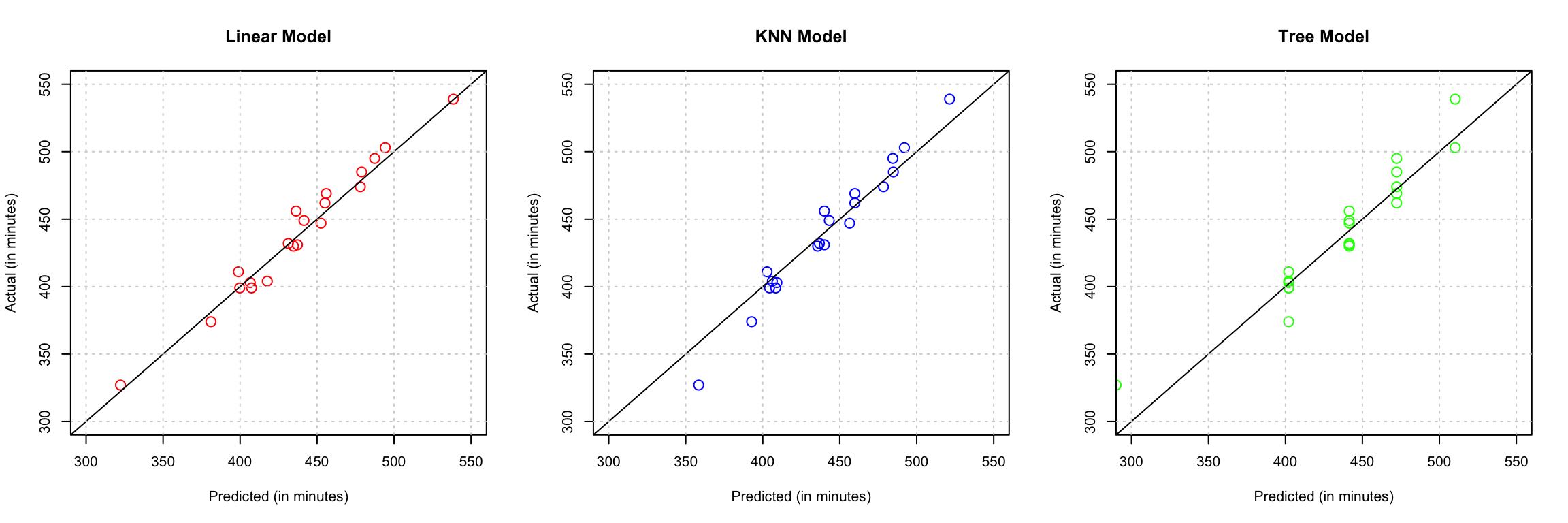
5 Discussion
After calculating the Rooted Mean Squared Error (RMSE) which gives us an estimate of the average squared prediction error in the original units used by the response variable for the validation data, we can see that the linear model (without transformation) possess the lowest value of RMSE.
## [1] 9.1931Shown above is the value for our Test RMSE. In our linear model, the test RMSE and our validation RMSE is very similar which means there might be a little to no chance of overfit. Moreover, the plot for our linear model looks reasonable enough. Therefore, the linear model is our best model.
We are trying to predict the total sleep time based only the past data and one predictor which is very hard if we do not account a seasonal factor that could potentially result in limitations of our analysis. For instance, there might be a day where the observed person is very tired thus, he only spends a very little time in bed (’time_bed’) before he fell asleep. The inability to adjust our analysis to the seasonality effects may lead to false interpretations of the results from the analysis. Therefore, due to the RMSE value and limitations, using sleep tracking devices are still the best way to track our total sleep time even though our prediction is close enough to the actual value.
Future directions: We should consider using more variable as our predictor and also put the seasonal factor into account. By doing so we might further increase the accuracy of our predicted values.
6 Appendix
6.1 Data Dictionary
start_time- The date and time which the device detected the user has gone to bed due to lack of motion. (But not necessarily started sleep.)end_time- The date and time which the device detected that the user is no longer in bed, due to motion.min_asleep- The total sleep time, in minutes. This is meant to estimate a clinical measure of sleep. (Not simply time in bed.)min_awake- The time spent in bed, but awake, in minutes.num_awake- The number of times the user “awoke” during their time in bed.time_bed- Duration betweenstart_timeandend_time. The sum ofmin_asleepandmin_awake. In other words, total time in bed, in minutes.min_rem- Total time spent in REM sleep, in minutes.min_light- Total time spent in light sleep, in minutes.min_deep- Total time spent in deep sleep, in minutes.
6.2 EDA
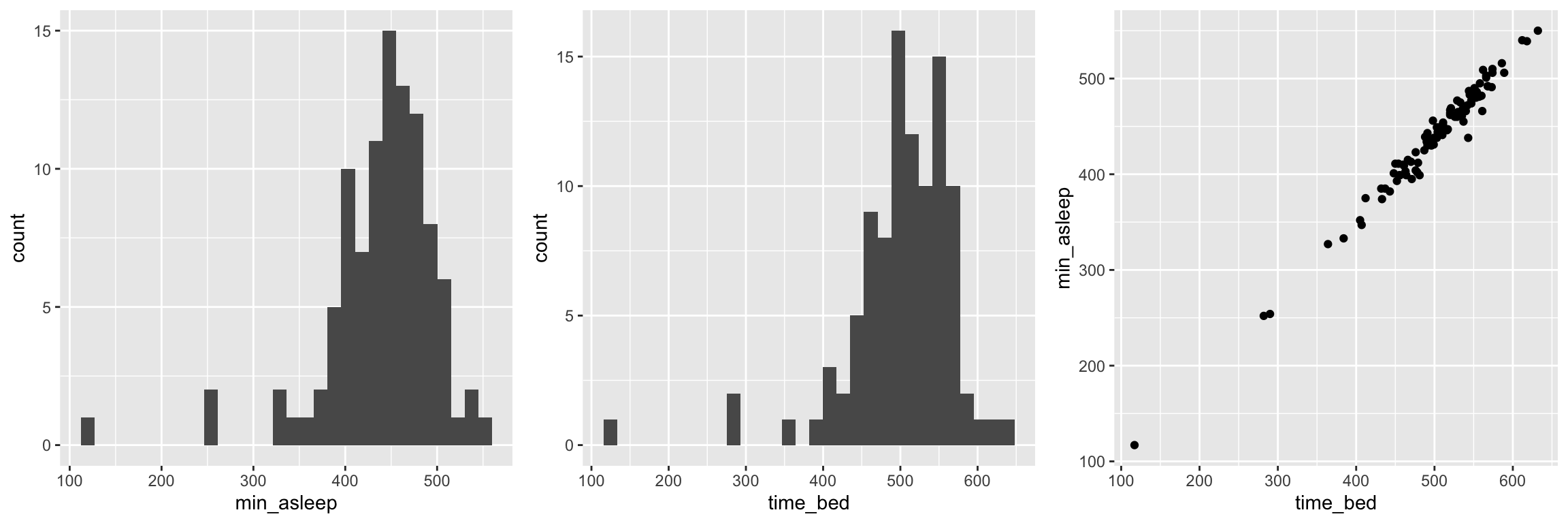
Consumer sleep tracking devices: a review of mechanisms, validity and utility↩
Everything you need to know about sleep, but are too tired to ask↩
The author would like to note that Fitbit makes it incredibly difficult for users to obtain their own data.↩
Vincent Oktavianus
Student / Course Assistant
Fresh college graduate with a Bachelor of Science major in Statistics from the University of Illinois at Urbana-Champaign. Proficient in R and Data Analysis, skilled in Python and SQL. Seeking opportunities in data analyst/data science roles.